
Statistique Canada
www.statcan.gc.ca
Liens de la barre de menu commune
 Consulter la version la plus récente.
Consulter la version la plus récente.Contenu archivé
L'information indiquée comme étant archivée est fournie aux fins de référence, de recherche ou de tenue de documents. Elle n'est pas assujettie aux normes Web du gouvernement du Canada et elle n'a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
Annexe C Statistiques utilisées dans l'étude du biais d'échantillonnage
On mentionne au chapitre 6 que selon le mode d'échantillonnage aléatoire, la valeur
![]()
suivra une distribution à peu près normale (0,1). Une justification de ceci est donnée ici. L'échantillonnage a été fait indépendamment pour chaque UC. Par conséquent, ![]() est la somme de H variables aléatoires indépendantes, où H est le nombre de
UC au Canada. Comme il y a 46 510
UC au échantillonnés au Canada, alors H est très élevé. Par conséquent, selon le théorème central limite,
est la somme de H variables aléatoires indépendantes, où H est le nombre de
UC au Canada. Comme il y a 46 510
UC au échantillonnés au Canada, alors H est très élevé. Par conséquent, selon le théorème central limite, ![]() suivra une distribution à peu près normale (0,1) (voir Kendall et Stuart, 1963, p. 193), tout comme
suivra une distribution à peu près normale (0,1) (voir Kendall et Stuart, 1963, p. 193), tout comme ![]() si
si ![]() .
. ![]() , cependant, n'aurait pas une moyenne de 0 si les échantillons de ménages au niveau des UC présentaient un biais important, pour quelque raison que ce soit.
, cependant, n'aurait pas une moyenne de 0 si les échantillons de ménages au niveau des UC présentaient un biais important, pour quelque raison que ce soit.![]()
Calculons maintenant une autre statistique permettant de vérifier si le biais est le même entre deux régions ou deux recensements. Soit ![]() et
et ![]() des estimateurs (fondés sur les poids initiaux) des chiffres de population connus
des estimateurs (fondés sur les poids initiaux) des chiffres de population connus ![]() et
et ![]() pour deux régions géographiques ou deux recensements. Soit
pour deux régions géographiques ou deux recensements. Soit ![]() et
et ![]() les biais relatifs de
les biais relatifs de ![]() et
et ![]() . Nous voulons vérifier si l'hypothèse nulle
. Nous voulons vérifier si l'hypothèse nulle ![]() est vraie. Pour ce faire, on peut utiliser la statistique
est vraie. Pour ce faire, on peut utiliser la statistique
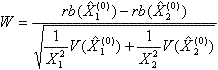
où ![]() et
et ![]() sont des estimateurs non biaisés de
sont des estimateurs non biaisés de ![]() et
et ![]() respectivement. Par conséquent, si l'hypothèse nulle
respectivement. Par conséquent, si l'hypothèse nulle ![]() ci-dessus est vraie, l'espérance de
ci-dessus est vraie, l'espérance de ![]() est zéro. Il convient également de prendre note que le dénominateur de
est zéro. Il convient également de prendre note que le dénominateur de ![]() est l'erreur type du numérateur de
est l'erreur type du numérateur de ![]() (il n'y a pas de terme de covariance parce que les estimations établies pour des régions différentes ou des recensements différents sont indépendantes), de sorte que
(il n'y a pas de terme de covariance parce que les estimations établies pour des régions différentes ou des recensements différents sont indépendantes), de sorte que ![]() a une variance de 1. Maintenant si
a une variance de 1. Maintenant si ![]() suit une distribution à peu près normale (encore selon le théorème central limite),
suit une distribution à peu près normale (encore selon le théorème central limite), ![]() suivra aussi une distribution à peu près normale, tout comme
suivra aussi une distribution à peu près normale, tout comme ![]() et
et ![]() . Par conséquent,
. Par conséquent, ![]() suit une distribution à peu près normale (0,1) si l'hypothèse nulle
suit une distribution à peu près normale (0,1) si l'hypothèse nulle ![]() est vraie.
est vraie.